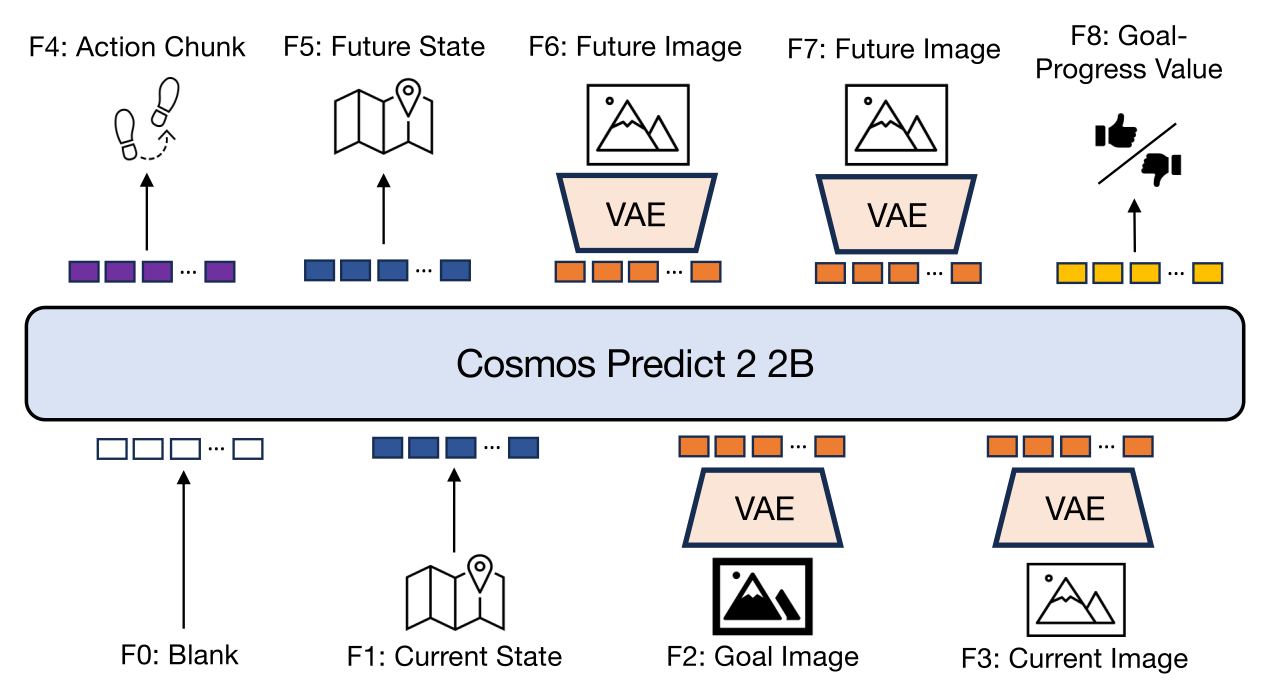
NavWAM represents goal-conditioned navigation as denoising a fixed nine-frame latent canvas built on the pretrained
Cosmos Predict 2 (2B) video world model.
The bottom four frames are observed and condition the denoising process: a blank pad frame required by the causal VAE,
the current robot state, a goal frame (the target image in our image-goal setting), and the current egocentric observation.
The top five frames are generated as prediction targets: the executable action chunk, the future state,
two future egocentric observations, and the goal-progress value.
Following the latent-frame principle of Cosmos Policy, non-visual variables (state, action, value) are encoded
as latent frames rather than as separate output heads, so a single model jointly predicts visual and non-visual navigation variables.
A single set of weights is trained with three conditioning modes sampled per training sample — a
policy mode (50%) that predicts the action chunk, future state, future images, and value;
a world-model mode (25%) that additionally conditions on the action; and a
value mode (25%) that estimates goal progress.
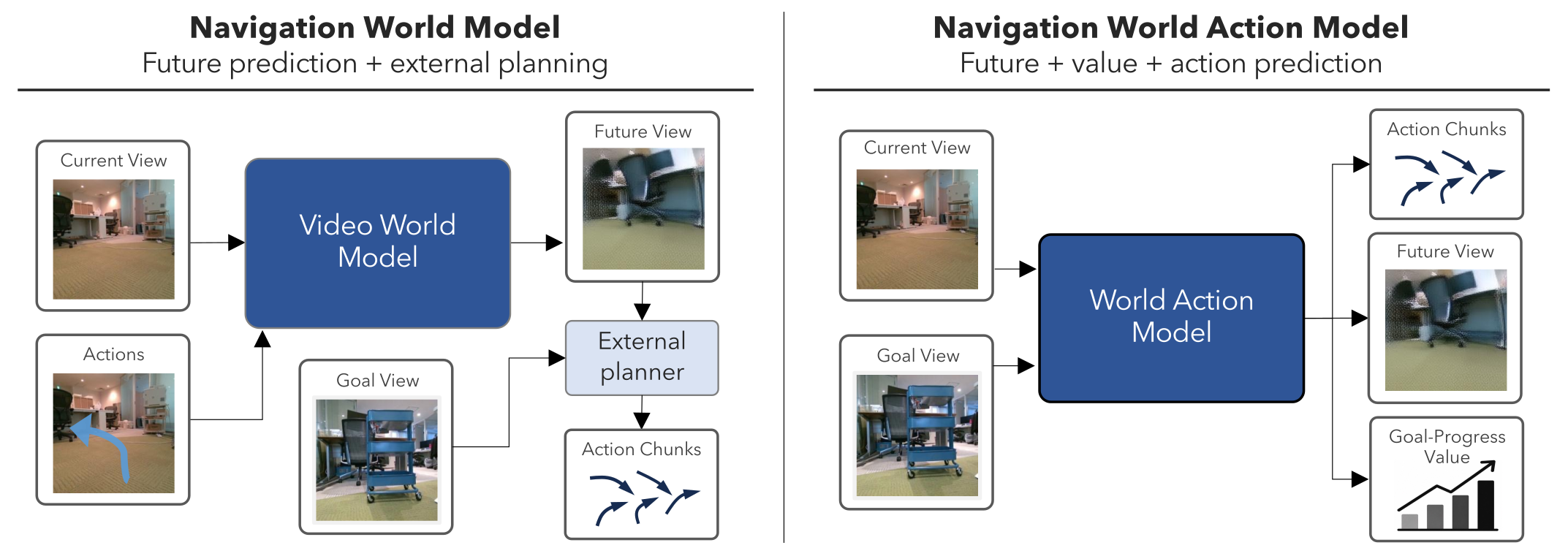
At inference, NavWAM runs in its policy mode: it directly outputs an action chunk, executes it in a receding-horizon loop,
and re-queries the model — producing future-view and value predictions as interpretable foresight without any external planner.